お! できたかという顔をしている柴犬です。
概要
前回、CSVファイルのデータを読み込んで配列(構造体)に値をセットできました。
今回は、その構造体をクイックソートします。
その結果をCSVファイルに書き出します。
デコード、エンコードがない分楽かなと思いましたが、マルチバイト、ワイド文字があったりと他の言語ではない知識が必要です。
アセンブリ言語を書きやすくするために派生した言語と改めて思いました。
最初のダメコード
strcmp を使って文字列の大小を判定しました。コンパイルはできましたが実行してみるとソートができてなかったり、落ちるなど散々たる結果に終わりました。
よくよく調べてみると strcmp ではなく wcscmp を使わなければいけないようです。
#include <stdlib.h>
#include <stdio.h>
#include <wchar.h>
#include <locale.h>
#include <string.h>
#define N 1200000
struct records
{
char f1[40];
char f2[50];
};
struct records record[N];
void quicksort(struct records *record, int left, int right);
void swap(struct records *record1, struct records *record2);
int getposi(struct records *record, int left, int right);
int main()
{
FILE *fin;
FILE *fout;
wchar_t *res;
int f;
setlocale(LC_CTYPE, "");
fin = fopen("./input.csv", "r");
fout = fopen("./output.csv", "w");
const wchar_t *const separator = L",";
int count = 0;
for (;;)
{
wchar_t str[90];
f = 0;
if (fgetws(str, sizeof(str) / sizeof(str[0]), fin) == NULL)
{
if (feof(fin))
{
// ファイルの終わり
break;
}
else
{
fputs("エラーが発生しました。\n", stderr);
exit(EXIT_FAILURE);
}
}
wchar_t *token = wcstok(str, separator);
while (token != NULL)
{
/* wprintf(L"%ls\n", token); */
if (f == 0)
{
res = wcsncpy(record[count].f1, token, 20);
}
else
{
res = wcsncpy(record[count].f2, token, 30);
}
f += 1;
token = wcstok(NULL, separator);
}
/* wprintf(L"%ls\n", record[count].f1); */
/* wprintf(L"%ls\n", record[count].f2); */
fwprintf(fout, L"%ls\n", str);
count += 1;
}
wprintf(L"%ls\n", record[count - 1].f1);
wprintf(L"%ls\n", record[count - 1].f2);
printf("\nData has been getten...%d\n", count);
quicksort(record, 0, count - 1);
fclose(fin);
fclose(fout);
wprintf(L"%ls\n", record[count - 1].f1);
wprintf(L"%ls\n", record[count - 1].f2);
printf("\nFile has been created...%d\n", count);
return 0;
}
void quicksort(struct records *record, int left, int right)
{
int posi;
if (left < right)
{
posi = getposi(record, left, right);
if (posi > 0)
{
quicksort(record, left, posi - 1);
}
quicksort(record, posi + 1, right);
}
return;
}
int getposi(struct records *record, int left, int right)
{
char *pivot1;
char *pivot2;
// 軸を右端
pivot1 = record[right].f1;
pivot2 = record[right].f2;
// 開始位置
int i = left;
int j;
// 昇順にするため左に小さいもののエリア
for (j = left; j < right; j++)
{
// pivotより小さいものが見つかった
if (strcmp(pivot1, record[j].f1) > 0)
{
swap(&record[i], &record[j]);
// 次の交換位置
i += 1;
}
else if (strcmp(pivot1, record[j].f1) == 0)
{
if (strcmp(pivot2, record[j].f2) > 0)
{
swap(&record[i], &record[j]);
// 次の交換位置
i += 1;
}
}
}
// pivotの位置iが定まったので交換
swap(&record[i], &record[right]);
// 位置を返す
return i;
}
void swap(struct records *record1, struct records *record2)
{
struct records temp;
temp = *record1;
*record1 = *record2;
*record2 = temp;
return;
}2000行を実行してみました。実行から瞬時にソートできました。
しかし、作成できたCSVファイルの中を見るとソートできていません。
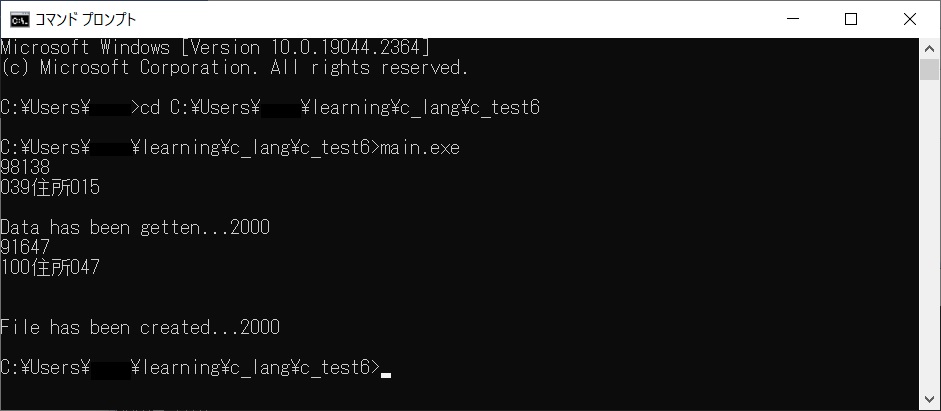
期待を持って100万行を実行してみましたが、ソートの段階で落ちました。
見直したコード
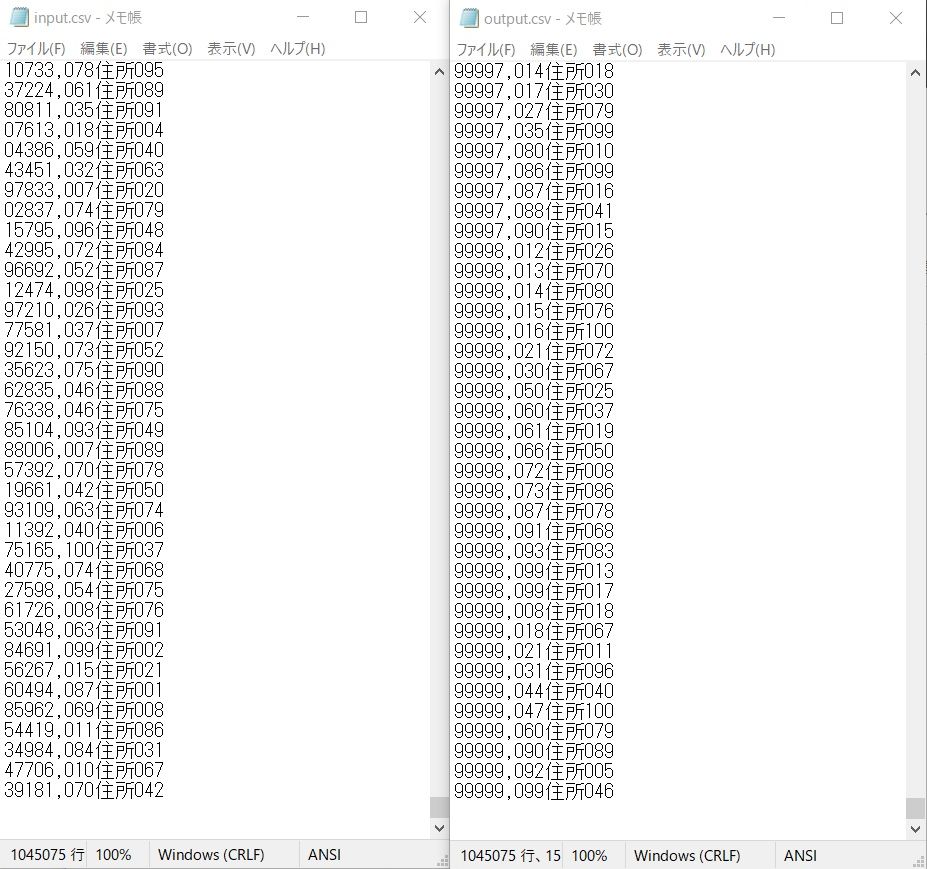
美しくないコードですが、一応CSVファイルが作成できました。
ソートも間違っていないし、欠けた行もありません。
malloc を使うなどさらに完成度を高めたいと思います。
ソートのアルゴリズムをちょっと変えました。
#include <stdlib.h>
#include <stdio.h>
#include <wchar.h>
#include <locale.h>
#include <string.h>
#define N 1200000
struct records
{
char f1[40];
char f2[50];
};
struct records record[N];
void quicksort(struct records record[], int left, int right);
void swap(struct records *record1, struct records *record2);
int getposi(struct records record[], int left, int right);
int main()
{
FILE *fin;
FILE *fout;
wchar_t *res;
int f;
setlocale(LC_CTYPE, "");
fin = fopen("./input.csv", "r");
fout = fopen("./output.csv", "w");
const wchar_t *const separator = L",";
int count = 0;
for (;;)
{
wchar_t str[90];
f = 0;
if (fgetws(str, sizeof(str) / sizeof(str[0]), fin) == NULL)
{
if (feof(fin))
{
// ファイルの終わり
break;
}
else
{
fputs("エラーが発生しました。\n", stderr);
exit(EXIT_FAILURE);
}
}
wchar_t *token = wcstok(str, separator);
while (token != NULL)
{
if (f == 0)
{
res = wcsncpy(record[count].f1, token, 20);
}
else
{
res = wcsncpy(record[count].f2, token, 30);
}
f += 1;
token = wcstok(NULL, separator);
}
count += 1;
}
wprintf(L"%ls\n", record[count - 1].f1);
wprintf(L"%ls\n", record[count - 1].f2);
printf("\nData has been getten...%d\n", count);
quicksort(record, 0, count - 1);
int i = 0;
for (;;)
{
if (i == count)
{
break;
}
fwprintf(fout, L"%ls", record[i].f1);
fwprintf(fout, L"%ls", L",");
fwprintf(fout, L"%ls", record[i].f2);
i += 1;
}
fclose(fin);
fclose(fout);
wprintf(L"%ls\n", record[count - 1].f1);
wprintf(L"%ls\n", record[count - 1].f2);
printf("\nFile has been created...%d\n", count);
return 0;
}
void quicksort(struct records record[], int left, int right)
{
int posi;
if (left < right)
{
posi = getposi(record, left, right);
quicksort(record, left, posi - 1);
quicksort(record, posi + 1, right);
}
return;
}
int getposi(struct records record[], int left, int right)
{
char *pivot1;
char *pivot2;
// 軸を左端
pivot1 = record[left].f1;
pivot2 = record[left].f2;
// 開始位置
int i = left + 1;
int j = right;
// 昇順にするため左が小さいもののエリアにしています
// 無限ループにしています。
while (1)
{
// 条件が真の間 i を進めます。
while (wcscmp(pivot1, record[i].f1) > 0 || (wcscmp(pivot1, record[i].f1) == 0 && wcscmp(pivot2, record[i].f2) > 0))
{
// 次の位置
i += 1;
}
// 条件が真の間 j を進めます。
while (wcscmp(record[j].f1, pivot1) > 0 || (wcscmp(record[j].f1, pivot1) == 0 && wcscmp(record[j].f2, pivot2) > 0))
{
// 次の位置
j -= 1;
}
// 結果、交差したら終了
if (i >= j)
{
break;
}
// 交差していなければ交換
swap(&record[i], &record[j]);
}
// pivotの位置iが定まったので交換
swap(&record[left], &record[j]);
// 位置を返す
return j;
}
void swap(struct records *record1, struct records *record2)
{
struct records temp;
temp = *record1;
*record1 = *record2;
*record2 = temp;
return;
}
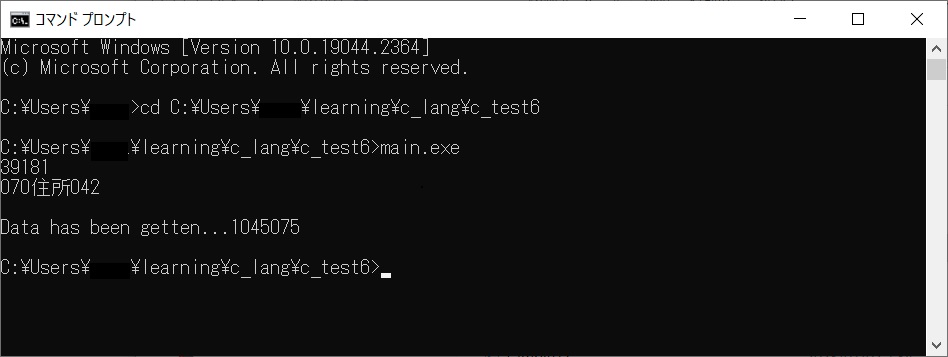
実行してみたところ、5秒弱でCSVファイルを作成できました。
体感的にはソートはまじで速かったです。
思うこと
改めて GO 、Python のとっつきやすさは半端じゃないと感じました。あと、R も同じようなことをしてみようと思います。
その時は、また投稿します。