
今日は暑いな。早くもこもこの冬毛がなくならないかな。という顔をしている柴犬です。
概要
Python に備わっているビルトイン map と Pandas の Series.map をまとめてみました。
いろいろ本などを読みましたが、
Python Pandas のそれぞれの公式ページを読むのが一番いいような気がします。
Built-in map
Pyhton の方式ホームページによると
https://docs.python.org/3/library/functions.html#mapBuilt-in map について次のような説明があります。
map(function, iterable, *iterables)
function を iterable の全ての要素に適用して結果を生成 (yield) するイテレータを返します。
追加の iterables 引数が渡された場合、 function は渡された iterable と同じ数の引数を取らなければならず、関数は全ての iterable から並行して得られた要素の組に対して適用されます。
複数の iterable が渡された場合、そのうちで最も短い iterable が使い尽くされた段階で止まります。返すのはイテレータですので、map(function, iterable)では値を表示できません。
list(map(function, iterable))としてリストに変換して表示するようにします。
例
例1
iterable が [“a”, “b”, “c”, “d”, “e”] の例です。
val = ["a", "b", "c", "d", "e"]
list(map(str.upper(), val)))
例2
iterable が range(10) -> [0, 1, 2 ・・・ 9]で
*iterables が repeat(5) -> [5, 5, ・・・5・・Endless] の例です。
実行の結果が、pow(0,5), pow(1,5), pow(2,5), pow(3,5) ・・・ pow(4,5)となっているのが分かります。
def repeat(object, times=None):
if times is None:
// Endless
while True:
yield object
else:
for i in range(times):
yield object
list(map(pow, range(10), repeat(5)))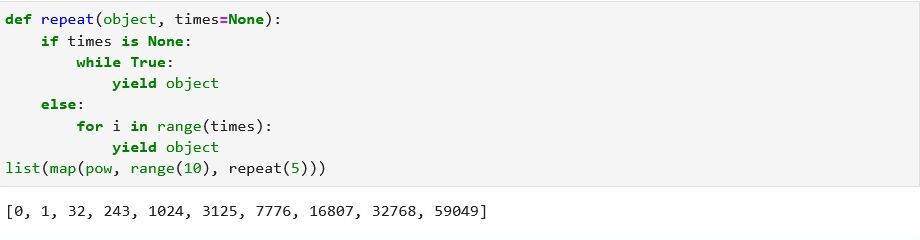
例3
lambda 関数を使ってみます。
val = [x for x in range(10)]
list(map(lambda x: x**2, val))
pandas.Series.map
Pandas の方式ホームページによると
https://pandas.pydata.org/docs/reference/api/pandas.Series.map.htmlpandas.Series.map について次のような説明があります。
Series.map(arg, na_action=None)[source]
マッピングまたは関数に従って Series の値を別の値に置き換えるために使用します。
パラメータ
arg function, collections.abc.Mapping subclass or Series
値の交換。
na_action {None, ‘ignore’}, default None
「ignore」の場合、マッピングに渡さずに NaN 値を伝播します。
リターン
Seriesarg が、collections.abc.Mapping subclass でもよいことに注目します。
Mapping は任意のキー探索をサポートしていて、 collections.abc.Mapping の 抽象基底クラス で指定された特殊メソッド __getitem__()、__iter__()、__len__() を実装しているコンテナオブジェクトです。
例えば、 dict, collections.defaultdict, collections.OrderedDict, collections.Counter などです。
例
例1
ディクショナリ( dict )を使ってみます。
import pandas as pd
s = pd.Series(["tokyo","chiba","oosaka","kyoto"])
t = s.map({"tokyo": "kanto", "chiba": "kanto", "oosaka": "kinki", "kyoto": "kinki"})
t
例2
ユーザー関数を使ってみます。
def addcontry(x):
return f'日本_{x}'
s = pd.Series(["tokyo","chiba","oosaka","kyoto"])
list(s.map(addcontry))
例3
lambda 関数を使ってみます。
s = pd.Series(["tokyo","chiba","oosaka","kyoto"])
list(s.map(lambda x: f'日本_{x}'))
例4
Class を使ってみます
class Country:
def __init__(self, colname):
self.colname = colname
def __repr__(self):
return f"'日本_{self.colname}'"
s = pd.Series(["tokyo","chiba","oosaka","kyoto"])
list(s.map(Country))